Azure Data Factory Parameters
How to improve productivity developing pipelines in Azure Data Factory using parameters.
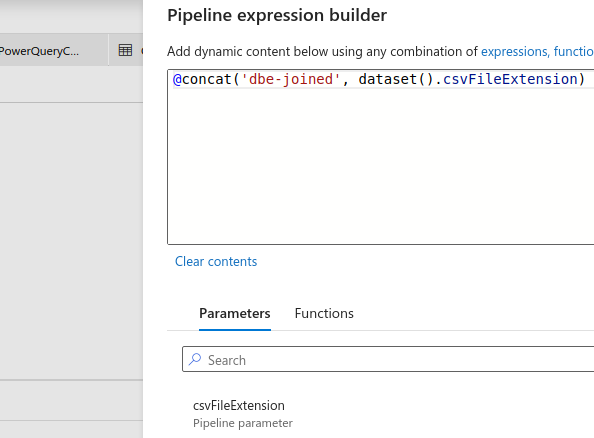
Here is an example of an expression with a parameter:
@concat('dbe-joined', dataset().csvFileExtension)
The function @concat concatenates the string dbe-joined and the value of dataset().csvFileExtension, where csvFileExtension is a user-defined parameter with string value csv. Therefore this silly example will result in dbe-joined.csv
You can also use variables which can be modified with the Set variable activity to control a workflow.
Setup this tutorial
Follow this post Build a Pipeline with Azure Data Factory for details.
- Create a resource group
- Create a Blob Storage account
- Create a container and upload a CSV file
- Create an Azure SQL Database
- Create a table that maps to the CSV columns
- Create a Data Factory
- Create a Linked Service to Blob storage
- Create a Dataset for Blob storage called
InputCSV - Create a Linked Service to Azure SQL
- Create a Dataset for Azure SQL
OutputSQL - Create a Pipeline called
CSVtoSQL - Create a Copy Activity with source Blob dataset and sink SQL dataset
- Click
Debug - Verify the CSV was copied to the SQL database
Setup many CSVs and SQL tables
Upload more CSV files in Blob Storage and create the corresponding SQL tables.
Given these uploaded files:
- FactSales.csv
- DimCustomer.csv
- DimProduct.csv
- DimAddress.csv
- DimStore.csv
Then create a table in Azure SQL for each CSV
- FactSales
- DimCustomer
- DimProduct
- DimAddress
- DimStore
Create Parameters in the Datasets to copy one or more CSVs
Instead of manually creating datasets (Blob + SQL) for each additional CSV. Create parameters for the datasets.
Given these datasets created previously:
- Dataset for Blob storage called
InputCSV - Dataset for Azure SQL
OutputSQL
Go to InputCSV:
- On the tab
Parameters- Click on
New - Enter as name
fileNameof typeStringwith emptyValue
- Click on
- On the tab
Connection- On the
File Path - On the
Filefield, click onAdd dynamic content - Under
Parameters, click onfileName - This creates the expression
@dataset().fileName
- On the
Go to OutputSQL
- On
Parameters, clickNewand enter as nametableNameof typeString - On
Connections, click onEditand replace the current table name. - Click on
Add dynamic content - Select the parameter
tableName - This creates the expression
@dataset.tableName
Go to the Copy Activity
- The source has the parameter
fileName - The sink has the parameter
tableName Debugwith one of the CSVs- In Source
fileNameenterDimCustomer.csv - In Sink
tableNameenterDimCustomer - Click
Debugand verify in SQL Server that the CSV was copied to the table
- In Source
Create Parameters in the Pipeline
In the ADF Pipeline, click on the canvas. There are four tabs:
- Parameters
- Variables
- Settings
- Output
Instead of creating parameters in the datasets, you can create parameters scoped to the pipeline.
- On the
Parameterstab, click onNew - Enter
fileNametypeString - Enter
tableNametypeString
In Copy Activity
- The source has the parameter
fileName- The current value is
DimCustomer.csv - Click on this field,
dynamic content - Select the pipeline parameter
fileName - The expression says
pipeline().parameters.fileName
- The current value is
- The sink has the parameter
tableName- The current value is
DimCustomer - Do the same change but select the parameter
tableName - The expression says
pipeline().parameters.tableName
- The current value is
Click Debug
- This will ask for the parameters values corresponding to
fileNameandtableName
This tutorial is based on Adam’s video on Youtube here where he explains using parameters in ADF.
