BigQuery SQL Subtract Two Aggregations By Date
In BigQuery SQL how to subtract values of two aggregations by date.
Use Cases
- Covid confirmed cases in the last N days
- Product inventory count in the last N days
- Sales revenue in the last N days
Using as example the Johns Hopkins COVD-19 dashboard here. How to calculate the 28-Day Cases value for a specific country?
Open BigQuery and select the dataset covid19_jhu_csse. Then select the table summary. Looking at the schema, we need these fields:
country_region STRING
date DATE
confirmed INTEGER
Confirmed cases are aggregated from the previous date
Looking at the preview and querying the dataset, you can see that there are multiple rows per country for different provinces for the same date. However, the numbers looked really high by the date they stopped reporting the data.
For example, find confirmed cases in Florida in March 2023. You would assume by now the cases would be very low:
SELECT `date`, confirmed
FROM `bigquery-public-data.covid19_jhu_csse.summary`
WHERE country_region = 'US'
AND province_state = 'Florida'
AND `date` BETWEEN '2023-03-01' AND '2023-03-09'
First 3 rows show:
Row date confirmed
1 2023-03-09 89806
1 2023-03-09 10746
1 2023-03-09 56189
Narrow down finding cases in Miami in the same date range:
SELECT `date`, confirmed
FROM `bigquery-public-data.covid19_jhu_csse.summary`
WHERE country_region = 'US'
AND province_state = 'Florida'
AND admin2 = 'Miami-Dade'
AND `date` BETWEEN '2023-03-01' AND '2023-03-09'
ORDER BY `date` ASC
First 3 rows show:
Row date confirmed
1 2023-03-01 1538402
1 2023-03-02 1538402
1 2023-03-03 1552197
Subtract two aggregation values by date
Get the value of the latest date
From an interface point of view, a user might select a date range, including a start date, and end date.
For this example, I am assuming the end date is the latest date in the table.
DECLARE endDate Date DEFAULT (SELECT MAX(`date`) FROM `bigquery-public-data.covid19_jhu_csse.summary`);
This returns a date value 2023-03-09
Get the start date in the range (28 days ago)
DECLARE startDate Date DEFAULT (DATE_SUB(endDate, INTERVAL 28 DAY));
Create a function to get the aggregated value for each date
CREATE TEMP FUNCTION confirmedCasesByDate(dateValue DATE)
RETURNS INT64
AS
((
SELECT SUM(confirmed)
FROM `bigquery-public-data.covid19_jhu_csse.summary`
WHERE
country_region = 'Japan'
AND
`date` = dateValue
));
Call the function to subtract the two aggregations
SELECT
confirmedCasesByDate(endDate) - confirmedCasesByDate(startDate)
AS
confirmed_last_28_days;
Output vs JHU Dashboard
Query output: 418671
JHU Covid Dashboard, select Japan, 28-Day Cases: 418,671
BigQuery SQL Subtract Two Aggregations By Date
DECLARE endDate Date DEFAULT (SELECT MAX(`date`) FROM `bigquery-public-data.covid19_jhu_csse.summary`);
DECLARE startDate DEFAULT (DATE_SUB(endDate, INTERVAL 28 DAY));
CREATE TEMP FUNCTION confirmedCasesByDate(dateValue DATE)
RETURNS INT64
AS
((
SELECT SUM(confirmed)
FROM `bigquery-public-data.covid19_jhu_csse.summary`
WHERE
country_region = 'Japan'
AND
`date` = dateValue
));
SELECT
confirmedCasesByDate(endDate) - confirmedCasesByDate(startDate)
AS confirmed_last_28_days;
Human vs ChatGPT: Optimize query to run faster
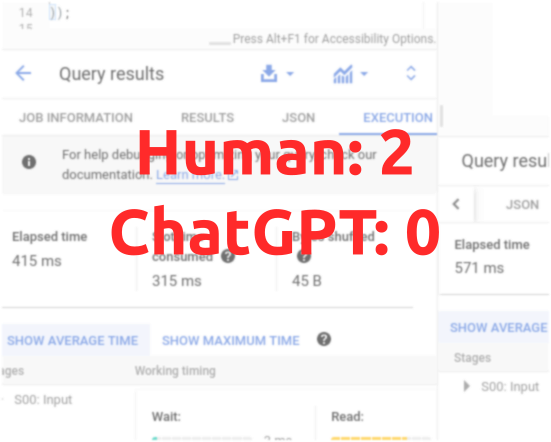
My query ran in 415 ms. I wondered if it could be faster so I asked ChatGPT.
It answered:
One way to optimize this SQL query is to reduce the number of times that the confirmedCasesByDate function is called. This can be achieved by modifying the query to calculate the sum of confirmed cases for the entire 28-day period in a single SQL query, rather than by calling the function for each individual date in the period.
However, the code was not what I was trying to achieve, which was refactoring to not repeat myself with the same code. It didn’t use a function, and instead used the same selection twice. I ran that code and it took 571 ms.
Human: 1 ChatGPT: 0
Partition the table by date to make queries faster
Created another dataset and queried the example table to see the query speed.
CREATE OR REPLACE TABLE `eda-datasets.jhu_covid_v2.confirmed_2023`
PARTITION BY `date`
AS
SELECT * FROM `bigquery-public-data.covid19_jhu_csse.summary`
Then ran the same script above to get the confirmed cases in Japan. It was faster with 380 ms.
Partition details:
Table type: PartitionedPartitioned by: DAYPartitioned on field: dateNumber of partitions: 1,143
Cluster the table by country to check the difference
First drop the table or it will complain that it cannot modify a table with a different partition:
DROP TABLE `eda-datasets.jhu_covid_v2.confirmed_2023`;
Then create the table with partition and cluster:
CREATE OR REPLACE TABLE `eda-datasets.jhu_covid_v2.confirmed_2023`
PARTITION BY `date`
CLUSTER BY `country_region`
AS
SELECT * FROM `bigquery-public-data.covid19_jhu_csse.summary`;
In the Table info a new field says:
Clustered by: country_region
Run the script again to see confirmed cases in Japan. It was slower with 435 ms
Query Speed Comparison
| Strategy | Time in ms |
|---|---|
| Human Not Partitioned | 415 |
| ChatGPT Not Partitioned | 571 |
| Human Partitioned | 380 |
| Human Partitioned and Clustered 1st run | 435 |
| Human Partitioned and Clustered 2nd run | 399 |
Score:
Human: 2 ChatGPT: 0